Introduction
Artificial Intelligence (AI) is rapidly transforming numerous aspects of our lives, from healthcare and finance to autonomous driving and customer service. However, as AI systems become more complex and pervasive, the need for transparency and accountability grows. This is where Explainable AI (XAI) comes into play. XAI aims to make AI decisions transparent and understandable, fostering trust and enabling more informed decision-making.
What is Explainable AI (XAI)?
Explainable AI (XAI) refers to methods and techniques used to make the decision-making processes of AI systems transparent and understandable to humans. The goal of XAI is to create AI models whose decisions can be easily interpreted and trusted by end-users, developers, and stakeholders. This is crucial in critical areas like healthcare, finance, and autonomous driving, where understanding the reasoning behind AI decisions is essential.
Key Aspects of Explainable AI
- Transparency: XAI aims to make the inner workings of AI models clear, providing insights into how models process data and make decisions.
- Interpretability: The outputs and decisions of AI systems should be interpretable, meaning users can understand how specific inputs influence the outputs.
- Justification: XAI provides reasons for the AI’s decisions, allowing users to trust and verify the system’s behavior.
- Trust and Accountability: By making AI systems explainable, stakeholders can hold these systems accountable and ensure they operate within ethical and legal boundaries.
- Debugging and Improvement: Explainability helps developers identify and correct errors or biases in AI models, leading to better performance and fairness.
How does Explainable AI Works?
Explainable AI (XAI) works by employing a variety of methods and techniques to make the decision-making processes of AI models transparent and understandable to humans.
The three categories of XAI are as follows:
- Explainable data: explains the type of data and content used to train the model, why it was selected, how fairness was determined, and whether any effort was needed to eliminate bias.
- Explanatory predictions: a list of all the model features that are used or activated to produce a particular result.
- Explainable algorithms: can be used to show the various layers that make up a model and explain how each one affects a prediction or an output.
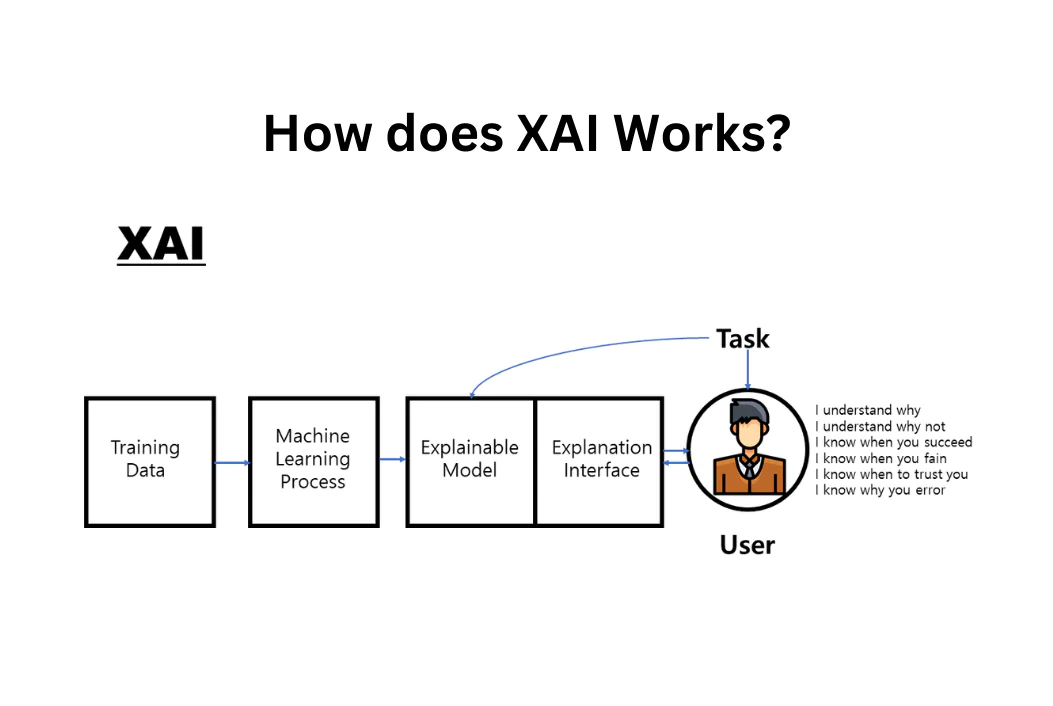
The main goal is to bridge the gap between complex machine learning models and human interpretability. Here’s a breakdown of how XAI works:
1. Model-Specific vs. Model-Agnostic Methods
-
Model-Specific Methods: These techniques are tailored to specific types of models and leverage the inherent structure of the models to provide explanations.
- Example: Decision Trees naturally provide clear explanations through their structure, showing how decisions are made based on feature splits.
-
Model-Agnostic Methods: These techniques can be applied to any machine learning model, regardless of its internal workings. They analyze the inputs and outputs of the model to generate explanations.
- Example: LIME (Local Interpretable Model-agnostic Explanations) approximates any model locally with a simpler, interpretable model to explain individual predictions.
2. Post-Hoc Explanation Methods
These methods are used after the model has been trained to provide insights into the decision-making process.
-
Feature Importance: Determines the significance of each feature in making predictions.
- Example: SHAP (SHapley Additive exPlanations) assigns an importance value to each feature, showing its contribution to the prediction.
-
Visualization Techniques: Create visual representations of how features influence the model’s decisions.
- Example: Partial Dependence Plots (PDPs) show the relationship between selected features and the predicted outcome.
-
Instance-Based Explanations: Provide explanations for individual predictions by analyzing how changing input features affects the output.
- Example: Counterfactual Explanations show what minimal changes to an input instance would change the model’s prediction.
3. Global vs. Local Explanations
-
Global Explanations: Aim to explain the overall behavior of the model across all predictions.
- Example: Global Interpretation via Recursive Partitioning (GIRP) uses decision trees to approximate the entire model and provide an interpretable global overview.
-
Local Explanations: Focus on explaining individual predictions, making it clear how specific input features lead to a particular output.
- Example: LIME provides local explanations by approximating the model’s behavior around a specific instance.
4. Rule-Based Explanations
These methods generate human-understandable rules that explain the model’s decisions.
-
Scalable Bayesian Rule Lists: Use Bayesian inference to create a list of interpretable rules that can explain the model’s classification decisions.
-
Anchors: Generate high-precision if-then rules that explain the predictions for specific instances.
5. Sensitivity Analysis
These methods analyze how sensitive the model’s predictions are to changes in input features.
-
Permutation Importance: Measures how the model’s performance changes when the values of a feature are randomly shuffled, indicating the feature’s importance.
-
Morris Sensitivity Analysis: Systematically varies input features to evaluate their impact on the model’s output.
6. Gradients and Attribution Methods
These techniques are primarily used for deep learning models to understand how changes in input values affect the output.
- Integrated Gradients: Calculate the average gradients of the model’s output with respect to the input features along a path from a baseline to the actual input.
7. Prototype-Based Methods
These methods identify representative examples from the dataset to explain model behavior.
- Protodash: Identifies a set of prototypes that best represent the data and the model’s decision-making process.
8. Model Simplification
These techniques create simpler, interpretable models that approximate the behavior of more complex models.
-
Tree Surrogates: Train a decision tree to mimic the predictions of a complex model, providing a simpler explanation.
-
Explainable Boosting Machine (EBM): Uses an interpretable model structure (generalized additive models) combined with boosting techniques to achieve both high accuracy and interpretability.
Workflow of XAI
- Model Training: A complex machine learning model is trained on data.
- Explanation Generation: Post-hoc or intrinsic methods are used to generate explanations for the model’s predictions.
- Evaluation and Validation: The generated explanations are evaluated for their accuracy, coherence, and usefulness to ensure they genuinely reflect the model’s behavior.
- User Interaction: Explanations are presented to users (e.g., developers, end-users, regulators) to enhance understanding, trust, and decision-making.
By implementing these methods, XAI ensures that AI systems are more transparent, interpretable, and trustworthy, enabling better oversight and more informed decision-making.
Techniques in Explainable AI
-
Model-Specific Methods:
- Linear Models: These are inherently interpretable as they directly show the relationship between input features and the output.
- Decision Trees: These provide a clear, visual representation of the decision-making process.
-
Post-Hoc Explanation Methods: These are applied after the model has been trained.
-
- Feature Importance: Methods like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) show the impact of each feature on the model’s predictions.
- Counterfactual Explanations: These show how altering input features would change the output, helping users understand decision boundaries.
-
Visualization Techniques: Tools like partial dependence plots and t-SNE (t-distributed Stochastic Neighbor Embedding) help visualize the relationship between features and the model’s decisions.
-
Natural Language Explanations: Generating explanations in natural language to describe the model’s reasoning in a human-friendly manner.
Types of Explainable AI Algorithms
1. SHAP (SHapley Additive exPlanations)
SHAP is a method based on cooperative game theory that assigns an importance value (Shapley value) to each feature of a model’s prediction. It provides a consistent and fair way to interpret the contribution of each feature to the final prediction.
2. LIME (Local Interpretable Model-agnostic Explanations)
LIME approximates complex models locally with interpretable models, such as linear models or decision trees, to explain individual predictions. It perturbs the input data and observes the changes in the output to determine feature importance.
3. Permutation Importance
Permutation importance evaluates the significance of each feature by randomly shuffling its values and measuring the decrease in model performance. It identifies which features the model depends on most by observing how the prediction accuracy changes when feature values are altered.
4. Partial Dependence Plot (PDP)
PDPs illustrate the relationship between a subset of features and the predicted outcome of a machine learning model. They show the average effect of the selected features on the prediction, helping to understand how changes in feature values influence the model output.
5. Morris Sensitivity Analysis
This method assesses the sensitivity of a model’s output to changes in input variables. It systematically varies each input feature and measures the impact on the output, identifying the most influential features.
6. Accumulated Local Effects (ALE)
ALE plots describe the effect of features on the prediction by considering their distribution and interactions with other features. Unlike PDPs, ALE plots correct for the influence of correlated features, providing more accurate insights into feature importance.
7. Anchors
Anchors are specific, understandable rules that sufficiently explain a model’s decision for a given instance. These high-precision rules highlight conditions under which the model consistently makes the same prediction, providing clear, human-friendly explanations.
8. Contrastive Explanation Method (CEM)
CEM focuses on providing explanations that highlight what is present in an instance to make a certain prediction and what is minimally required to change the prediction. It identifies both pertinent positive features (supporting the prediction) and pertinent negatives (required to change the prediction).
9. Counterfactual Instances
Counterfactual explanations show how altering an input instance would change the model’s prediction. They provide insights into the decision boundaries of the model, helping users understand what minimal changes could lead to different outcomes.
10. Integrated Gradients
Integrated Gradients attribute the prediction of deep neural networks to their input features by computing the average gradients along the path from a baseline to the input. This method ensures that the attribution is sensitive to changes in the input.
11. Global Interpretation via Recursive Partitioning (GIRP)
GIRP uses decision tree algorithms to provide a global, interpretable model that approximates the behavior of a complex model. It recursively partitions the feature space to create an understandable representation of the model’s decision process.
12. Protodash
Protodash identifies representative examples (prototypes) from the dataset that best summarize the model’s behavior. These prototypes serve as interpretable references for understanding how the model makes predictions across different instances.
13. Scalable Bayesian Rule Lists
This method constructs a list of interpretable rules using Bayesian inference. The resulting rule list provides a transparent and human-understandable model, useful for classification tasks where interpretability is crucial.
14. Tree Surrogates
Tree surrogates involve training a decision tree to approximate the predictions of a more complex, black-box model. The decision tree provides a simpler and more interpretable representation of how the black-box model makes decisions.
15. Explainable Boosting Machine (EBM)
EBM is an interpretable model that combines the accuracy of machine learning with the interpretability of generalized additive models (GAMs). It builds models using boosted trees in a way that remains highly interpretable, showing the contribution of each feature to the prediction.
These methods and algorithms are part of the broader effort in Explainable AI to make complex models more transparent and understandable, fostering trust and accountability in AI systems.
Applications of XAI
- Healthcare: In medical diagnosis, XAI helps doctors understand and trust AI-assisted decisions.
- Finance: XAI aids in understanding risk assessments and loan approvals, ensuring compliance with regulations.
- Legal Systems: It helps explain judicial decisions made by AI, ensuring transparency and fairness.
- Autonomous Vehicles: XAI helps in understanding and improving decision-making processes in critical driving situations.
Future Challenges of Explainable AI

Explainable AI (XAI) is a promising field aimed at making artificial intelligence systems more transparent, trustworthy, and accountable. However, it faces several significant challenges that need to be addressed for it to reach its full potential.
- Lack of a Unified Definition of Explainability
One of the primary challenges in XAI is the absence of a universally accepted definition of what constitutes a good explanation. Different stakeholders—such as developers, end-users, and regulators—have varying needs and perspectives on what makes an explanation useful. For instance, a developer might seek detailed technical insights, whereas an end-user might prefer simple, intuitive explanations. This diversity in expectations makes it difficult to create a one-size-fits-all solution for Explainability.
- Overgeneralization and Ambiguity
As Zachary Lipton from Carnegie Mellon University highlights, there is a risk that the concept of explainability becomes too broad, diluting its effectiveness. Without a clear and focused understanding of what an explanation should achieve, efforts in XAI might result in explanations that are too vague or generic to be useful. This overgeneralization can hinder the ability of explanations to genuinely enhance understanding and trust.
- Trade-offs Between Complexity and Interpretability
Many high-performing AI models, such as deep neural networks, are inherently complex and not easily interpretable. Simplifying these models to make them explainable often involves a trade-off with their accuracy and performance. Striking the right balance between model complexity and interpretability is a persistent challenge, as oversimplification can lead to loss of critical information and underperformance.
- Evaluation of Explanations
Determining the effectiveness and accuracy of explanations is another complex issue. There are no standardized metrics or benchmarks for evaluating the quality of explanations provided by XAI methods. This makes it challenging to assess whether the explanations are truly aiding understanding or if they are misleading or incomplete.
- Dynamic and Evolving Models
AI models are often updated and retrained as new data becomes available. This dynamic nature of AI systems means that explanations need to be adaptable and updated accordingly. Maintaining the consistency and reliability of explanations over time is a significant challenge, especially as models evolve.
- Bias and Fairness
Explanations need to address and reveal potential biases within AI models. However, ensuring that explanations do not inadvertently introduce or obscure biases is difficult. Bias detection and mitigation require sophisticated methods that are themselves interpretable and trustworthy.
- Scalability
Applying XAI techniques to large-scale, real-world AI systems is challenging due to computational and practical constraints. Scalability issues arise when trying to generate detailed explanations for complex models operating on vast amounts of data in real-time.
- Regulatory and Ethical Considerations
As AI systems are increasingly subject to regulatory scrutiny, explanations need to meet legal standards for transparency and accountability. Ensuring that XAI methods comply with diverse regulatory requirements across different jurisdictions adds another layer of complexity.
Addressing the Challenges
To overcome these challenges, the field of XAI must focus on several key areas:
-
Developing Context-Specific Explanations: Tailoring explanations to the needs of different stakeholders and specific use cases can enhance their relevance and effectiveness.
-
Creating Standardized Metrics: Establishing clear criteria and benchmarks for evaluating the quality and utility of explanations can provide a more consistent and objective assessment.
-
Balancing Complexity and Simplicity: Research into methods that preserve the accuracy of complex models while offering meaningful interpretations is crucial.
-
Ensuring Dynamic Adaptability: Developing techniques that allow explanations to evolve with model updates can maintain their reliability over time.
-
Mitigating Bias Transparently: Incorporating bias detection and mitigation as part of the explanation process can help ensure fairness and trustworthiness.
-
Enhancing Computational Efficiency: Improving the scalability of XAI methods to handle large datasets and real-time processing is essential for practical deployment.
-
Aligning with Regulatory Standards: Ensuring that XAI techniques meet legal and ethical requirements can facilitate broader acceptance and compliance.
Conclusion
Explainable AI (XAI) represents a crucial step towards building AI systems that are not only powerful but also transparent, accountable, and trustworthy. While the field holds significant promise in enhancing the interpretability of complex models, it faces several challenges, including the lack of a unified definition of Explainability, the trade-offs between model complexity and interpretability, and the need for standardized evaluation metrics. By addressing these challenges, XAI can better serve the diverse needs of developers, end-users, and regulators, ensuring that AI systems operate ethically and transparently. As AI continues to integrate into various aspects of society, the development and adoption of effective XAI methods will be essential in fostering trust and understanding.
FAQ
1. What is Explainable AI (XAI)?
- Explainable AI (XAI) refers to methods and techniques designed to make the decisions of AI systems transparent and understandable to humans. The goal is to create models whose decision-making processes can be easily interpreted and trusted by users.
2. Why is Explainable AI important?
- XAI is important because it enhances transparency, trust, and accountability in AI systems. It allows users to understand how decisions are made, ensures that models are operating fairly, and helps in identifying and correcting biases.
3. What are some common XAI methods?
- Some common XAI methods include SHAP (SHapley Additive exPlanations), LIME (Local Interpretable Model-agnostic Explanations), Partial Dependence Plots (PDPs), Counterfactual Explanations, and Integrated Gradients. Each method has its own approach to providing insights into model behavior.
4. What are the main challenges in Explainable AI?
- The main challenges in XAI include the lack of a unified definition of explainability, the trade-offs between model complexity and interpretability, the difficulty in evaluating explanations, scalability issues, and ensuring that explanations meet regulatory and ethical standards.
5. How can XAI help in detecting and mitigating bias in AI models?
- XAI methods can reveal how different features influence model predictions, making it easier to identify biased patterns. By understanding the model’s decision-making process, developers can adjust the model or the training data to mitigate biases and ensure fairer outcomes.
6. What is the difference between global and local explanations in XAI?
- Global explanations provide insights into the overall behavior of the model across all predictions, while local explanations focus on explaining individual predictions. Global explanations are useful for understanding general model behavior, whereas local explanations help in interpreting specific instances.
7. How does XAI address the dynamic nature of AI models?
- Explainable XAI techniques must be adaptable to accommodate updates and changes in AI models. This requires methods that can provide consistent and reliable explanations even as models evolve over time.
8. Are there standardized metrics for evaluating XAI methods?
- Currently, there are no universally accepted standardized metrics for evaluating XAI methods. Developing such metrics is an ongoing area of research to ensure that explanations are accurate, meaningful, and useful.
9. Can Explainable AI XAI methods be applied to any AI model?
- Model-agnostic XAI methods, such as LIME and SHAP, can be applied to any AI model, regardless of its internal structure. However, some XAI methods are model-specific and tailored to particular types of models.
10. What is the future of Explainable AI?
- The future of XAI involves advancing techniques to provide more accurate and meaningful explanations, developing standardized evaluation metrics, and ensuring that XAI methods can handle the scale and complexity of real-world AI applications. As AI becomes more prevalent, the importance of XAI in promoting ethical and transparent AI practices will continue to grow.
Learn about Latest AI Tools and AI Blogs.


Very interesting points you have remarked, appreciate it
for putting up.Raise blog range